


Introduction to Text Processing: Let's Build a Fast Dictionary in Python (Part 1)

Table of Contents
[Part 1]
- Importance of text processing (text processing)
- What is a dictionary lookup (what this article covers)
- Basic Concept of Trie Trees (TRIE)
- About double arrays
[No.2]
[No.3]
[No.4]
Importance of text processing (text processing)
My name is Kawakami from Takadensha's Development Office.
Currently, natural language processing using neural networks is flourishing.
At Kodensha, we are also working on neural translation (NMT), an application task of
neural networks, while utilizing the technology we have cultivated in conventional rule-based translation (RBMT) and statistical translation (SMT).
In the world of natural language processing, an important technology that serves as the warp and weft is text processing.
In this article, as an introduction to text processing, I will show you how to create a dictionary program
for those who know Python to some extent. The goal is to make the implementation as simple and practical as possible.
The example program in this article uses Python 3.6.x on jupyter-notebook.
What is a dictionary lookup (what this article covers)
The purpose of the lexical lookup program is to retrieve
the desired string (headword; e.g., the string of a Wikipedia headline) from some text data (e.g., a Wikipedia article).
To simplify our discussion, we will consider an exact match search with a headword.
If a text data is searched and a string of a headword registered in the dictionary is found,
the meaning of the word registered in advance is displayed. For this word sense, you may want to
store it in a
database (especially a non-relational database such as a key-value store). Leaving this for another time, we will focus only on
the first half, "search," and look at how search indexes work.
Basic Concept of Trie Trees (TRIE)
When we talk about string matching search, associative arrays come to mind first.
Python's standard dict is another example. Another one to keep in mind is the
Trie tree (trie), which is not included in the standard Python library, so let's make one.
The following figure shows an example of a Trie tree. The "*" marks the end of a word.
Let's count how many words are stored.
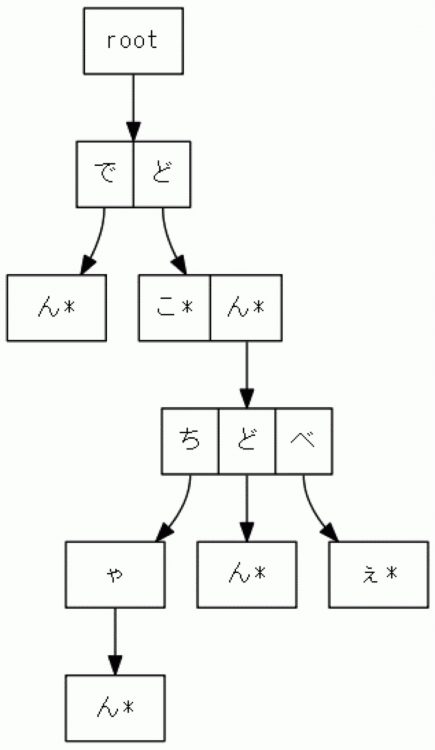
Let's trace from the root to "*".
There are six words: "den," "doko," "dong," "dongchan," "dongdon," "dongdon," and "dongbe.
The square next to the "↓" is the child node, which represents the next letter, and the square next to it is the
sibling node, which represents the choice of letters in the same position.
Strictly speaking, we consider that "a node transitions to the next node according to the character data", so
the character data is written at the arrow (edge). (Please refer to the academic literature for more details.)
To make the implementation even easier, let's make it a binary tree.
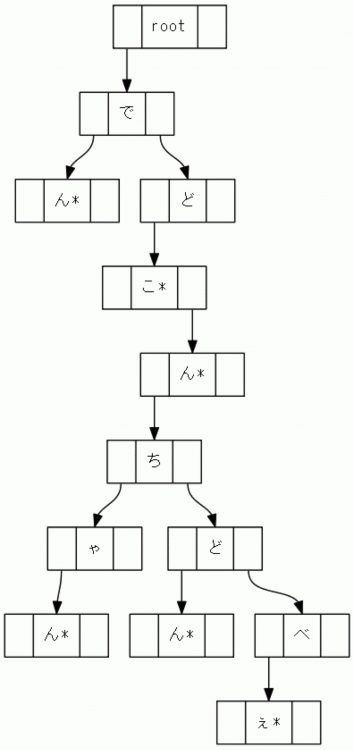
For humans, this is harder to understand than the first diagram, but the basics are the same. In the Trie tree in this diagram,
the nodes on the left side with "↓" are the children's nodes and the nodes on the right side with "↓" are the siblings' nodes.
Nodes marked with "*" are called leaf nodes.
In this way, we can look up a dictionary by searching for characters from the root to the leaf node one after another.
Let us consider the implementation. First, create a class for the node. As members:
- Index number of the left node
- Index number of the right node
- Character data that the node has (or its character code)
- Number of the data record of the word meaning when it is a leaf node (for example, -1 when it is not a leaf node)
The above seems to be all that is needed. Next, we create a class for the Trie tree.
First, let's have the nodes (13 in the way shown above) as an array.
Then, write methods for registering and searching nodes in the Trie tree, and you are done (?).
Even with such a simple design and implementation, fast searches are possible and
fully useful for various tasks in natural language processing. I used to write such Trie tree programs in Python or C++11 when dealing with huge amounts of text data
.
About double arrays
Now, here's the thing: Trie trees come in a variety of designs and implementations.
The current mainstream algorithm is called double array.
It has a long history, having been proposed more than 20 years ago, but the threshold for understanding it was a bit high.
Until recently, it was treated like a "tool for the experts".
Nowadays, you can read very easy-to-understand and easy-to-comprehend explanations, so it has become a technology that even ordinary people (in layman's terms, people with normal comprehension like me
) can reach.
Double Arrays Understandable to an Information Master"
http://d.hatena.ne.jp/takeda25/20120219/1329634865
He is a pioneer in easy-to-understand explanatory articles that can be read on the web.
Theory and Implementation of Morphological Analysis"
https://www.amazon.co.jp/dp/4764905779
The bible book on morphological analysis. There is an excellent explanation in Chapter 4, although it is only a few pages long.








