


Natural Language Processing / Text Processing

Tools for high-speed searching of large bilingual corpora
This module is useful for removing noise from text data and searching for similar sentences or bilingual texts.
It can be used regardless of the field of the target bilingual corpus.
It can be used regardless of the field of the target bilingual corpus.
Purpose of use
This technology can be used to extract similar sentences from a large amount of text data.
In addition to this, tools for building terminology dictionaries are also available.
In addition to this, tools for building terminology dictionaries are also available.
Example of processing screen

Flow example 1
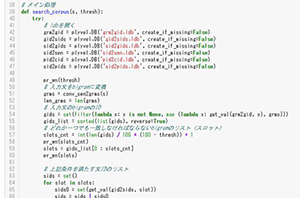
Flow example 2
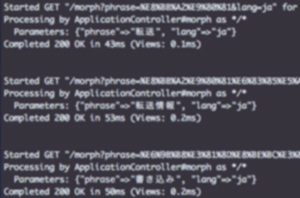
Flow example 3
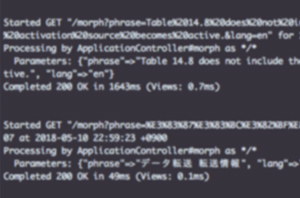
Flow example 4
Input sentences and search results
- Input Text
- I am going to Shanghai by plane.
- Search Results
- He decided to go to Shanghai by plane. Decided to sit on a leapfrog in Shanghai.
- Early next month I am going to Shanghai. I will leave for Shanghai at the beginning of the second month..
- I often fly but I am not good at it. I usually sit in a leapfrog, But I don't like flying.
Trial Acceptance Form
Please fill out the form below to tell us what you would like to try.
You can check the video of the operation screen recorded by our company.
Message from the Engineer
We have created a special algorithm to search for similar sentences, in addition to the usual exact match and partial match searches.
We have also devised a speed-up mechanism to perform such searches from hundreds of thousands of sentences.
This mechanism can be applied to many things, such as dictionary example search and translation memory.
It runs on Linux and can be accessed with a browser.
We have also devised a speed-up mechanism to perform such searches from hundreds of thousands of sentences.
This mechanism can be applied to many things, such as dictionary example search and translation memory.
It runs on Linux and can be accessed with a browser.



